
本文基于 BrowserMCP/mcp 开源仓库、官方文档 与 Browser MCP 官网 整理撰写;安装与配置过程截图为本人实测截取,仅用于技术介绍与学习交流。
如果你已经在用 Cursor 写代码,大概率也遇到过这种尴尬:
AI 能帮你改后端、写脚本、生成测试用例,但一到「打开网页、点按钮、填表单、验证页面是否真的跑通」,它往往就卡住了——它没有你的眼睛,也没有你的浏览器。
于是常见的工作流变成:让 AI 写好代码 → 你自己切到浏览器手动点一遍 → 发现问题,再把截图或报错贴回对话里。这一步「人肉桥接」,既慢,也容易漏。
Browser MCP 通过 MCP(Model Context Protocol)+ Chrome 扩展,把 Cursor 和你本机正在用的 Chrome 连起来,让 AI 直接操作你已登录的页面,而不必再开一个「无登录态、容易被风控」的自动化浏览器。
项目在 GitHub 上已有 6k+ Star(以仓库页为准)。本文讲清楚:它是什么、为什么值得试、Cursor 怎么配,以及场景与风险边界。
一、Browser MCP 是什么?
一句话:Browser MCP = 本机 MCP Server + Chrome 扩展,让 Cursor、Claude、Windsurf、VS Code 等支持 MCP 的应用,能自动化当前这台机器上的浏览器标签页。
| 官方表述 | 实际意味着什么 |
|---|---|
| ⚡ Fast | 本地执行,不走远程浏览器农场,延迟低 |
| 🔒 Private | 浏览器操作留在本机(不等于对话内容不上云,见第七节) |
| 👤 Logged In | 复用现有 Chrome Profile,不用每次重新登录 |
| 🥷 Stealth | 真实浏览器指纹,比无头自动化更不容易触发基础风控 |
它改编自微软 Playwright MCP,关键区别是接管你已有的浏览器,而不是另起一个无头实例。与 Playwright MCP 的选型对比见第五节。
二、为什么现在值得关注?
MCP 正成为 AI 工具链的「USB 接口」——把读文件、跑命令、查数据库、开网页等能力,从各家 IDE 的私有插件,变成可复用的协议层。
Browser MCP 补上了其中很大一块缺口:Web 仍是最主流的人机界面,AI 必须能「看见并操作」浏览器,才算真正进入很多真实工作流。
这类工具背后的思路也很清晰:不只是让 AI 多写几行代码,而是给它接上能稳定执行的环境——文件系统、终端、数据库之外,浏览器往往是缺的那一块。
三、架构、能力与官方演示
整条链路可以想成三段:
┌─────────────┐ MCP 协议 ┌──────────────────┐ WebSocket ┌─────────────────┐
│ Cursor 等 │ ◄──────────────►│ @browsermcp/mcp │ ◄─────────────►│ Chrome 扩展 │
│ │ (stdio) │ (本机 Node 进程) │ (本地通信) │ (控制真实标签页) │
└─────────────┘ └──────────────────┘ └─────────────────┘
- AI 应用通过 MCP 调用 Server 暴露的「浏览器工具」
- MCP Server(
npx @browsermcp/mcp)在本机启动,与扩展通信 - Chrome 扩展在已 Connect 的标签页上执行导航、点击、输入等动作
完整能力见 官网列表,核心是 Navigate、Click、Type、Snapshot(供 AI 理解页面结构)、Screenshot、Get Console Logs 等——偏「用户行为模拟」,而非底层爬虫协议。
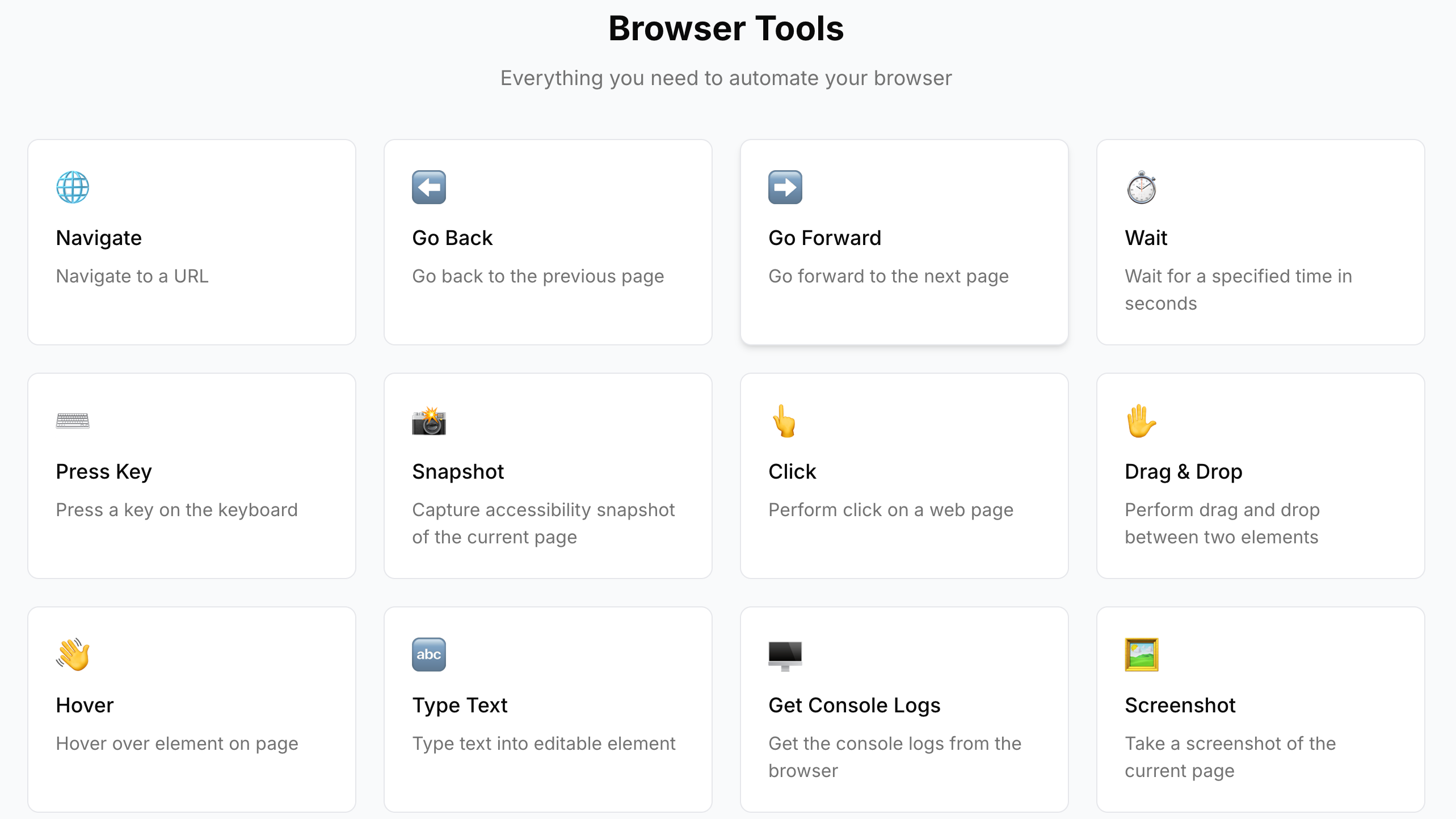
官网 Use Cases 展示了两类典型用法:在真实页面跑自动化测试(如回归点击、Console 校验),以及任务自动化(如搜索、填表)。完整演示视频见文末参考链接。


Chrome 扩展:Browser MCP - Chrome Web Store
四、Cursor 关键操作全流程(实测)
下面按 官方文档 顺序,把从安装到跑通第一条自动化命令的关键步骤拆开。
前置条件:已安装 Node.js;使用 Chrome / Chromium 系浏览器。
步骤 1:安装 Chrome 扩展
- 打开 browsermcp.io/install 安装扩展
- 点击 Add to Chrome 完成安装
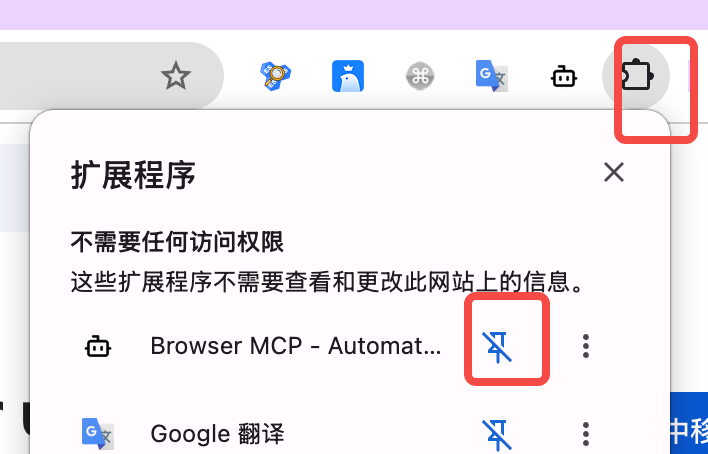
步骤 2:固定扩展并打开面板
- 在 Chrome 工具栏 Pin(固定) Browser MCP 扩展
- 点击扩展图标,打开 Browser MCP 面板
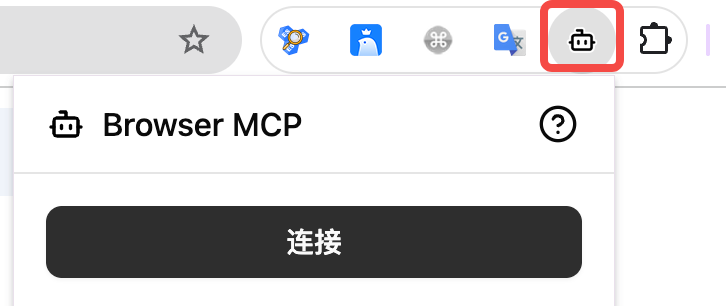
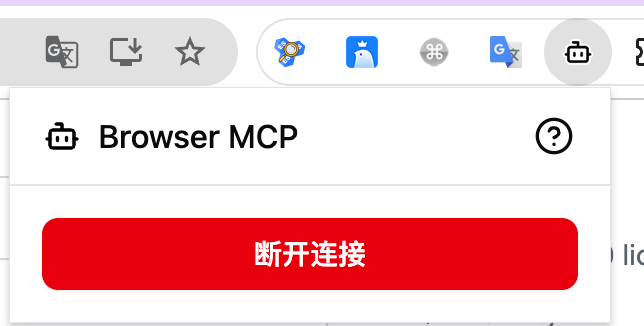
步骤 3:Connect —— 把「当前标签页」交给 MCP
这是最容易漏掉、也最关键的一步:
- 在 Chrome 中打开你希望被自动化的页面(例如
https://www.google.com或本地http://localhost:3000) - 在扩展面板点击 Connect
- 此后所有浏览器操作都会作用在已连接的这一 tab 上
步骤 4:在 Cursor 中添加 MCP Server
- 打开 Cursor 完整设置(Full Settings)→ Tools 标签
- 点击 New MCP server,粘贴下方 JSON
- 保存后,点击
browsermcp旁的 刷新 按钮重载 Server
也可写在项目级 .cursor/mcp.json 或用户级 ~/.cursor/mcp.json。
{
"mcpServers": {
"browsermcp": {
"command": "npx",
"args": ["@browsermcp/mcp@latest"]
}
}
}
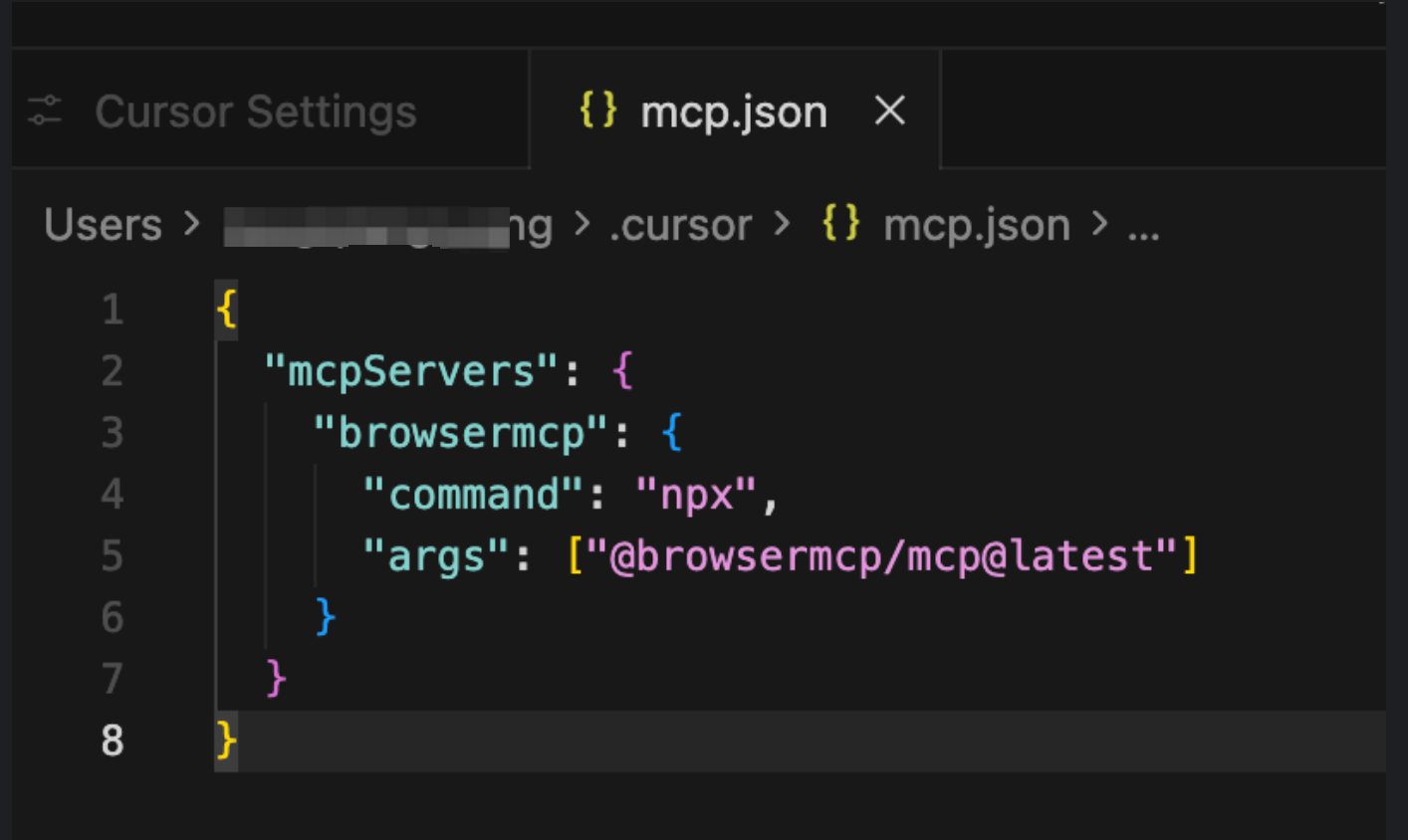
更多细节:Cursor MCP 文档、Browser MCP Server 配置。
步骤 5:确认 Server 已启用,排查常见报错
- MCP Server 必须处于 Enabled 状态,Cursor 才能调用浏览器工具
Client closed:把配置里的@browsermcp/mcp@latest改为@browsermcp/mcp(去掉@latest)后重载
国内/公司网络:Request timed out(-32001)
日志若出现 MCP error -32001: Request timed out,多半是 npm 源导致包拉不下来——Cursor 启动 MCP 时会执行 npx @browsermcp/mcp,Server 起不来就会超时。
终端快速自检:npm view @browsermcp/mcp version 失败,但加上 NPM_CONFIG_REGISTRY=https://registry.npmjs.org 能成功,即可确认是源问题。
推荐方案:全局安装 + 直接调用(最稳)
NPM_CONFIG_REGISTRY=https://registry.npmjs.org npm install -g @browsermcp/mcp
{
"mcpServers": {
"browsermcp": {
"command": "mcp-server-browsermcp"
}
}
}
若 Cursor 找不到命令(常见于 nvm),用 which mcp-server-browsermcp 查绝对路径填入 command。
备选:保留 npx,在配置里加 "env": { "NPM_CONFIG_REGISTRY": "https://registry.npmjs.org" },args 用 ["@browsermcp/mcp"](去掉 @latest)。改完后在 Settings → Tools & MCP 刷新 browsermcp。
| 阶段 | 表现 | 优先排查 |
|---|---|---|
| MCP 初始化 | Request timed out、工具列表为空 |
npm 源、npx 能否启动 Server |
| 工具调用 | Server 已 Enabled,但浏览器无反应 | 扩展是否 Connect、目标 tab 是否正确 |
更多排错见 官方 Troubleshooting。
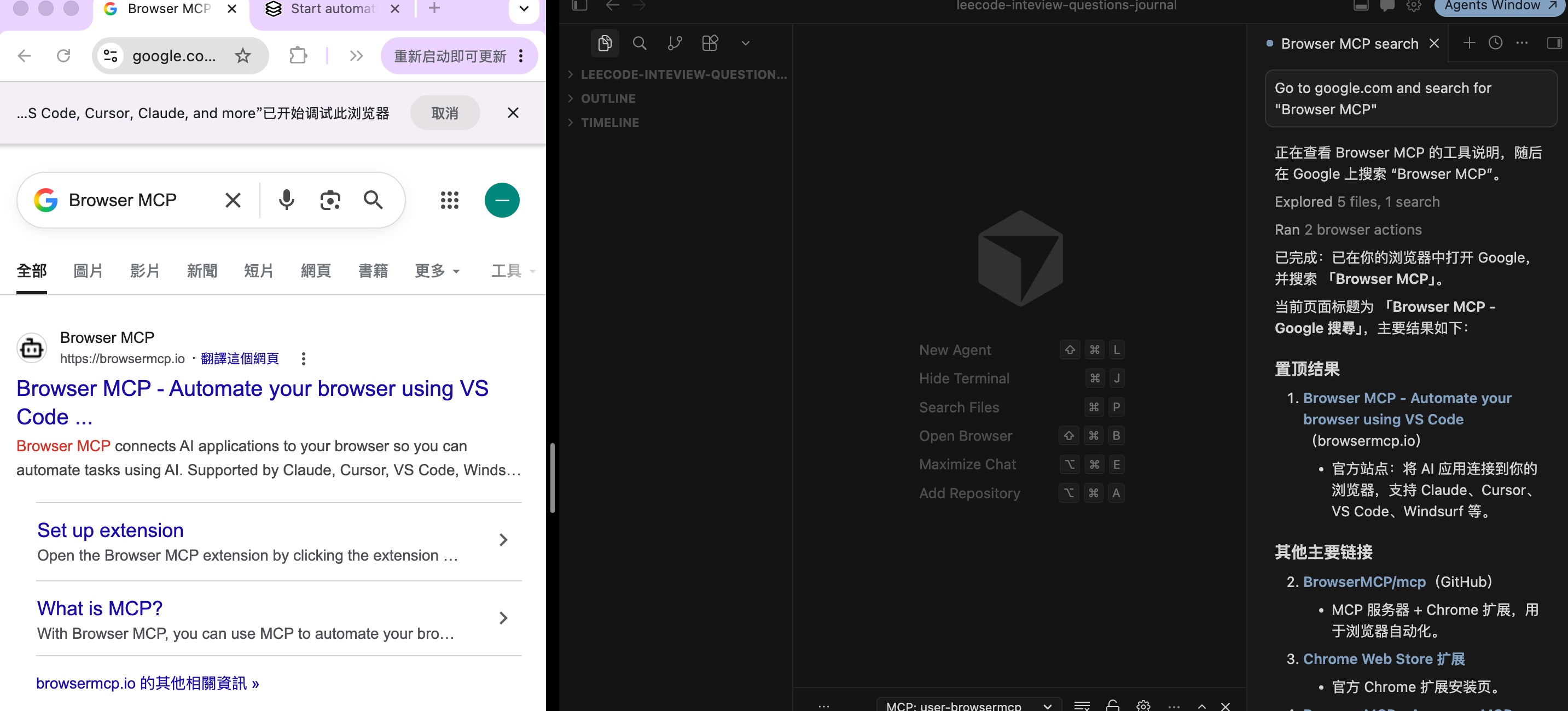
步骤 6:跑通第一条测试命令
扩展与 Server 都就绪后,在 Cursor Agent 中发送 官方示例:
Go to google.com and search for "Browser MCP"
或中文描述同等意图。预期:Cursor 调用 Navigate / Type / Click 等工具,已 Connect 的标签页自动跳转、搜索,Agent 返回页面信息或截图。
同一套 Server 配置也适用于 Claude Desktop、Windsurf、VS Code Copilot 等 MCP 客户端。
五、和 Playwright MCP 怎么选?
| 维度 | Browser MCP | Playwright MCP(微软) |
|---|---|---|
| 浏览器实例 | 复用你正在用的 Chrome | 通常启动独立/无头实例 |
| 登录态 | 天然继承本机 Profile | 需自行处理登录/Cookie |
| 风控与 CAPTCHA | 更接近真人浏览 | 更容易被识别为自动化 |
| 适用场景 | 已登录后台、个人效率、真实环境验证 | CI、干净环境、可重复 E2E 测试 |
不是谁替代谁,而是场景不同。 CI 流水线选 Playwright MCP;操作「只有在你浏览器里才进得去」的系统,Browser MCP 更顺手。复杂项目仍建议 Playwright/Cypress 进流水线,Browser MCP 作为开发阶段的加速器。
六、软件工程师可以怎么用?
1)前端改动的「最后一公里」验证
AI 改完组件后,打开本地 dev server,走一遍点击路径,用截图 + Console 判断是否真的修好。
2)内部系统 / 后台的半自动操作
很多公司内部平台没有完善 API,但 Web 界面齐全。Browser MCP 适合「AI 辅助操作员」。
3)多模型 Web 产品的横向体验
若同时在用多个 Web 版 AI 产品,Browser 自动化可以减少「切 tab、复制粘贴」的体力活。注意合规与平台 ToS。
4)运营/测试同学的重复任务
周期性填报、截图留存、简单回归点击——用自然语言描述流程,让 Agent 在真实浏览器里执行。
5)与「会交付的 AI」组合
单独 Browser MCP 只是多了一双「手」。若再叠加需求规范(Spec)、任务编排类 Agent 框架,才更接近「稳定交付」。
七、风险与边界
Browser MCP 很强大,但不是「把浏览器交给 AI 就万事大吉」。
它「知道」登录态,等于知道你的密码吗?
不等于。 Browser MCP 不会去读取 Chrome 密码管理器、已保存密码或 SSO 明文凭证。它只是在已 Connect 的标签页上,用现成的 Cookie / Session 模拟点击、输入——和你本人操作已登录页面,本质相同。
真正要警惕的是下面三类风险:
| 风险 | 说明 |
|---|---|
| 登录态被借用 | AI 不需要密码,就能在已登录 tab 里发消息、改配置、删数据、批量导出 |
| 页面内容进 AI 上下文 | Snapshot、截图、Console 日志会进入 Cursor 对话,可能进一步发给大模型——内部数据、Token、客户信息都有泄露面 |
| Prompt Injection | 恶意页面可在 DOM 中藏诱导指令,诱使 AI 在已登录状态下执行危险操作 |
官方说的 Private,主要指浏览器操作不走远程浏览器农场、Cookie 不托管给第三方——不等于 AI 对话里的页面内容也绝对私密。本地执行 ≠ 模型上下文不上云。
实操建议
- Connect 前想清楚:这个 tab 登录的是什么账号?AI 误操作一次后果有多大?
- 不要让 AI 输入或口述密码——登录你自己完成,再让 AI 操作已登录页面
- 敏感系统用独立 Chrome Profile,或干脆不对银行、支付、核心生产后台 Connect
- 删数据、转账、发消息、批量导出等操作,务必人工确认后再执行
- 不用时 Disconnect;留意 Cursor 隐私策略,公司内网页面谨慎使用云端模型
其他边界
- 合规:自动化登录态下的批量操作可能触碰平台 ToS
- 稳定性:扩展断开、浏览器升级、MCP Server 未刷新都会导致不可用
- 工程边界:适合「你的环境、你的登录态」,不替代 CI 里的完整 E2E 测试矩阵
八、写在最后
Browser MCP 不是大模型,也不是 ChatGPT 套壳。它更像一层协议适配器:把浏览器接进 MCP 世界,让 Cursor 能触达 Web 这一侧的真实界面。
如果你已经在用 MCP 接文件系统、终端、数据库,却还没接浏览器,很多工作流会少掉关键一块——按第四节配一遍,几分钟就能跑通。当 AI 不仅能写代码,还能在已 Connect 的浏览器里把结果点给你看,上面那种「人肉桥接」会少很多来回。
参考链接
- 项目仓库:https://github.com/BrowserMCP/mcp
- 官方网站:https://browsermcp.io/
- 官方文档:https://docs.browsermcp.io/
- 官方演示视频:test-automation.mp4 / craigslist.mp4
- MCP 协议:https://modelcontextprotocol.io/
- Playwright MCP:https://github.com/microsoft/playwright-mcp
- Chrome 扩展:Browser MCP on Chrome Web Store